
En la gestión de proyectos tradicional, un error en producción dispara una alerta y un ticket para un ingeniero. En 2026, la latencia humana es inaceptable. Los Self-Healing Systems (Sistemas de Autocuración) utilizan agentes de IA para detectar, diagnosticar y parchear fallos de infraestructura o lógica en tiempo real, antes de que el usuario note la degradación.
Del ‘Uptime’ al ‘Self-Repair’
Un sistema de autocuración no solo reinicia un contenedor de Docker. Utiliza bucles de control cerrados para ejecutar tres funciones críticas:
- Detección de Anomalías Semánticas: Identifica cuando un agente de IA empieza a alucinar o a desviarse de su «Golden Dataset».
- Aislamiento de Fallos (Sandboxing): Si un nodo del grafo de decisión falla, el sistema redirige el tráfico a un flujo determinista seguro.
- Refactorización Dinámica: El sistema puede ajustar hiperparámetros (como la temperatura) o cambiar de modelo (fallback) automáticamente para recuperar la precisión requerida.
El papel del Jefe de Proyectos: Gestionar la autonomía del sistema
Como Project Manager técnico, tu reto no es «arreglar fallos», sino definir los políticas de autocuración. ¿Qué nivel de autonomía permitimos al sistema para auto-parchearse? ¿En qué punto la intervención humana es obligatoria?
Nota: La autocuración no es una solución mágica; es un arma de doble filo. Un sistema que se «arregla» a sí mismo sin una observabilidad extrema puede ocultar problemas estructurales graves bajo una capa de parches automáticos. La meta es la resiliencia, no la opacidad.
Stack para Resiliencia Agéntica
- Kubernetes Operators: Para la gestión de infraestructura auto-reparable.
- LangGraph Checkpoints: Para volver a estados anteriores del grafo cuando se detecta un razonamiento erróneo.
- Control Theory: Aplicación de principios de ingeniería de control a flujos de trabajo de IA.
Preguntas que te podrías estar haciendo
Sí, si no hay límites claros. El sistema debe operar bajo el principio de «mínimo privilegio» y todas sus acciones de reparación deben quedar registradas en un log inmutable para auditorías posteriores.
La HA intenta evitar la caída mediante redundancia. La autocuración asume que el fallo ocurrirá y tiene la lógica necesaria para resolverlo internamente.
Se puede empezar con implementaciones sencillas, como scripts de comprobación de salud (Health Checks) que reinicien servicios o cambien de API Key automáticamente si una falla.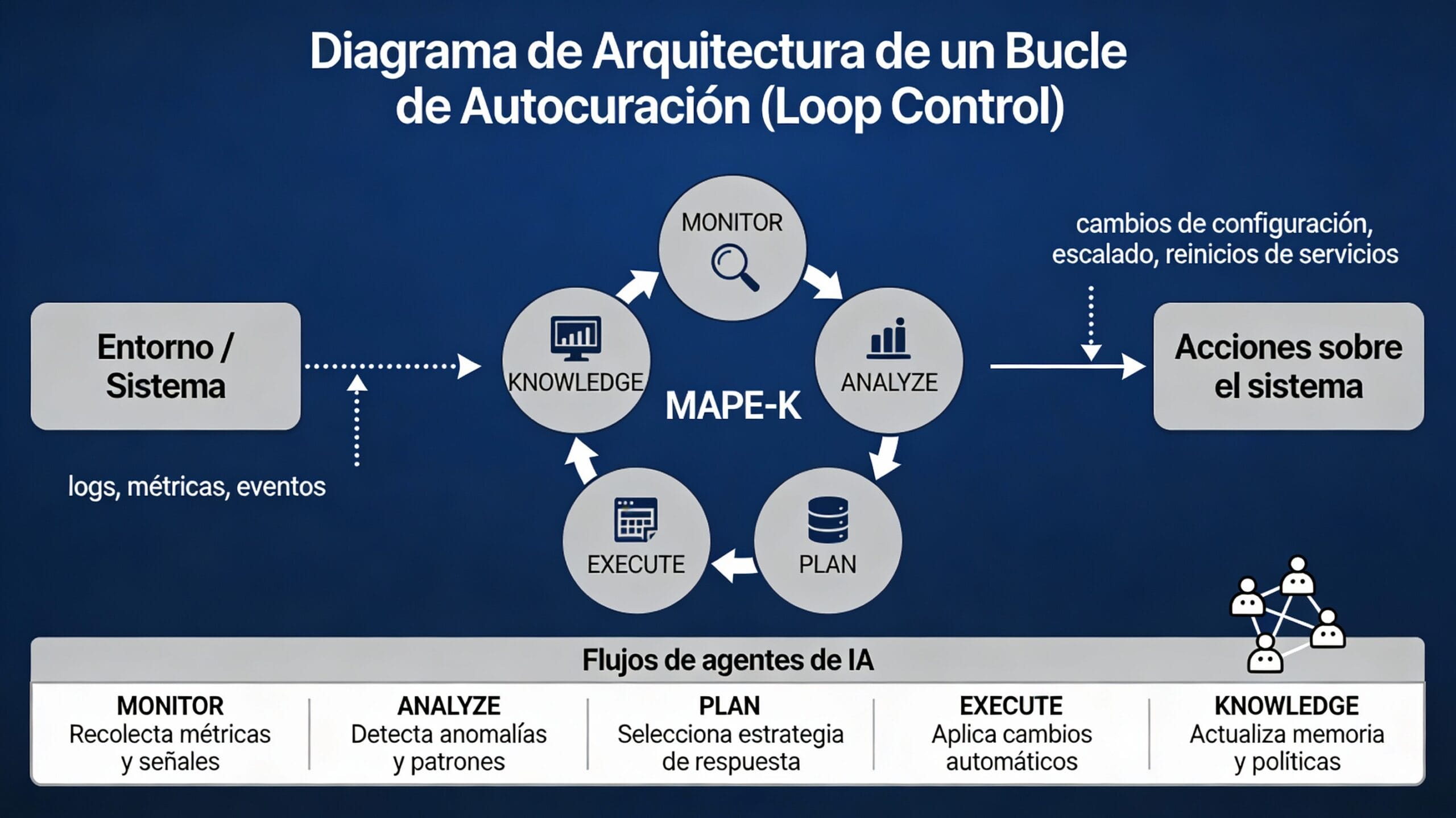
Referencias Técnicas
- IBM Research: «Architectural Blueprints for Autonomic Computing.»
- O’Reilly: «Cloud Native Infrastructure: Self-healing systems at scale.»
- Google SRE Book: «Addressing Cascading Failures.»
Autor
Antonio Gutiérrez es un Jefe de Proyectos IT con una amplia trayectoria en la dirección de equipos técnicos y el desarrollo de negocios online. Especialista en optimización de procesos y gestión de proyectos con tecnología IA, destaca por su capacidad para integrar soluciones innovadoras en entornos digitales complejos. Con una fuerte vocación por la formación y la responsabilidad profesional, Antonio se dedica a transmitir su experiencia en jefatura de proyectos para ayudar a otros a evolucionar en el sector tecnológico. Actualmente, ofrece consultoría estratégica y recursos especializados para profesionales que buscan liderar con éxito la transformación digital.


